车辆GPS轨迹数据是我们分析交通、物流等问题的重要基础,原始的GPS数据往往是无法直接使用的,设备精度、通信信息、气象条件等因素会导致很多轨迹点无法完美的匹配到相应的道路路径上,这就需要通过地图匹配对原始数据进行修正。地图匹配实际上是通过算法推测车辆的实际运行轨迹,对于非专业领域人员来说手动实现算法费时费力且效果不一定好,最佳方案当然是利用相对成熟的工具或第三方库。但现实是能找到的工具不是匹配效果差就是要收费,真正免费且好用的方案并不多,开源的Fast Map Matching就是其中一款。
Fast Map Matching项目本身的说明文档写的非常详细,多数问题可以查阅解决。在这里,为了降低大家的学习成本,同时结合个人的使用经验,对工具的整个安装使用过程和细节做进一步的说明。
资料网址
- FMM主页:https://fmm-wiki.github.io/
- Github:https://github.com/cyang-kth/fmm
- osm_mapmatching:https://github.com/cyang-kth/osm_mapmatching
- gps2traj:https://github.com/cyang-kth/gps2traj
安装
1、要点
- 虽然FMM提供了多系统支持,但强烈建议使用ubuntu系统,否则会在安装环节上消耗大量时间,除非你对各系统配置非常熟悉。
- 距离FMM最后更新已有差不多四年了,请特别注意依赖安装,版本号要一致,尽量使用新装系统作为运行平台。
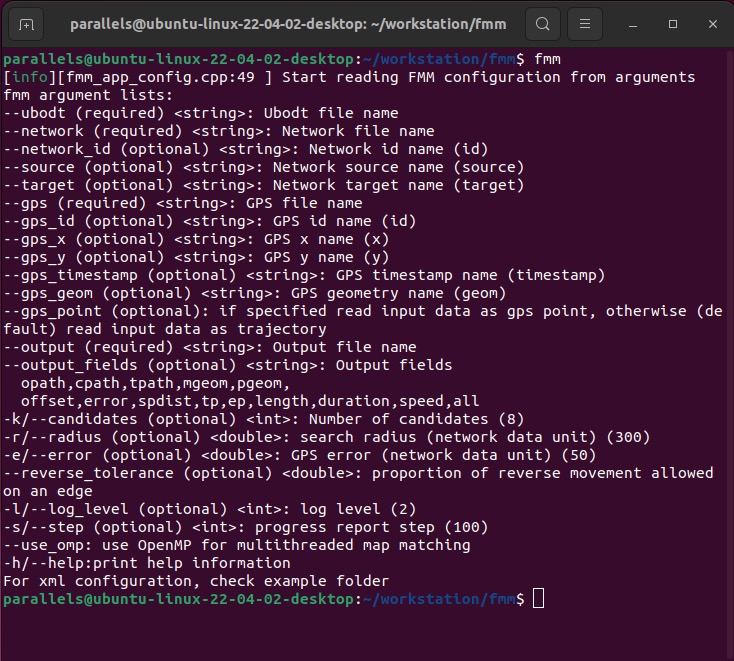
2、FMM安装步骤及命令「ubuntu 22.04」
# 1、添加apt仓库并升级
sudo add-apt-repository ppa:ubuntugis/ppa
sudo apt-get -q update
# 2、安装依赖, 在ubuntu22.04系统中会提示python-dev不存在,可以将下面的python-dev替换为
# python-dev-is-python3,若安装过程中出错,请到前述FMM主页中仔细核对依赖版本。
sudo apt-get install libboost-dev libboost-serialization-dev gdal-bin libgdal-dev make cmake libbz2-dev libexpat1-dev swig python-dev
# 3、从github上克隆项目到本地
git clone https://github.com/cyang-kth/fmm.git
# 4、进入fmm目录
cd fmm/
# 5、在fmm目录下新建build目录
mkdir build
# 6、再进入build目录
cd build
# 7、编译并安装
cmake ..
make -j4
sudo make install安装完成后,直接运行fmm 命令,出下如下界面表示安装成功
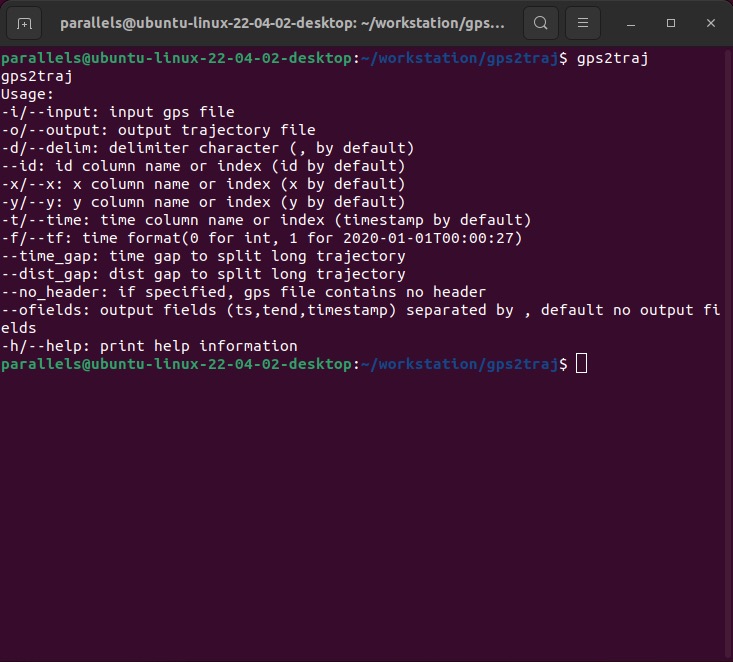
3、安装gps2traj
gps2traj是FMM作者提供的GPS点集与轨迹相互转换的工具,也就是点线互转工具,这个工具主要是为了方便后续地图匹配算法配置,及配置结果转为常用格式。相关安装命令如下:
# 1、克隆项目到本地
git clone https://github.com/cyang-kth/gps2traj.git
# 2、进入项目文件夹
cd gps2traj/
# 3、编译及安装项目
make
make install安装完成后,运行gps2traj 命令,出现帮助提示,说明安装成功。
4、安装OSMnx
安装OSMnx的目的主要是为了从开源地图网站下载基础路网数据,运行pip install osmnx 安装,osmnx 官方提供conda和docker安装,pip非官方支持,但安装相对简单一些,具体方式请参考以下网址:
https://osmnx.readthedocs.io/en/stable/installation.html
作者在osm_mapmatching这个案例中提供了下载OSM地图数据的脚本,同时将无向网络转换为有向网络。在vs code中新建文件osmdownload.py,放入以下代码,在「终端」中运行程序 python osmdownload.py,程序执行完毕后,当前文件夹下会多出一个「network-new」文件夹,这就是下载好的基础路网数据。当然,前述文件名和位置都是可以跟据需要自行修改的。这段代码核心还是利用osmnx库下载路网数据,具体的下载方式,如G = ox.graph_from_polygon(boundary_polygon, network_type='drive') 方法也可根据需要修改,拿到GPS数据后,往往需要先导入Arcgis,QGIS等软件进行预览,以确定需要下载路网数据的范围,请尽可能缩小这个范围,否则后续的地图匹配会占用大量计算资源。
import osmnx as ox
import time
from shapely.geometry import Polygon
from shapely.geometry import shape
import os
import numpy as np
import json
def save_graph_shapefile_directional(G, filepath=None, encoding="utf-8"):
# default filepath if none was provided
if filepath is None:
filepath = os.path.join(ox.settings.data_folder, "graph_shapefile")
# if save folder does not already exist, create it (shapefiles
# get saved as set of files)
if not filepath == "" and not os.path.exists(filepath):
os.makedirs(filepath)
filepath_nodes = os.path.join(filepath, "nodes.shp")
filepath_edges = os.path.join(filepath, "edges.shp")
# convert undirected graph to gdfs and stringify non-numeric columns
gdf_nodes, gdf_edges = ox.utils_graph.graph_to_gdfs(G)
gdf_nodes = ox.io._stringify_nonnumeric_cols(gdf_nodes)
gdf_edges = ox.io._stringify_nonnumeric_cols(gdf_edges)
# We need an unique ID for each edge
gdf_edges["fid"] = np.arange(0, gdf_edges.shape[0], dtype='int')
# save the nodes and edges as separate ESRI shapefiles
gdf_nodes.to_file(filepath_nodes, encoding=encoding)
gdf_edges.to_file(filepath_edges, encoding=encoding)
print("osmnx version",ox.__version__)
if __name__ == '__main__':
# Download by a bounding box
bounds = (17.4110711999999985,18.4494298999999984,59.1412578999999994,59.8280297000000019)
x1,x2,y1,y2 = bounds
boundary_polygon = Polygon([(x1,y1),(x2,y1),(x2,y2),(x1,y2)])
G = ox.graph_from_polygon(boundary_polygon, network_type='drive')
start_time = time.time()
save_graph_shapefile_directional(G, filepath='./network-new')
print("--- %s seconds ---" % (time.time() - start_time))
# Download by place name
place ="Stockholm, Sweden"
G = ox.graph_from_place(place, network_type='drive', which_result=2)
save_graph_shapefile_directional(G, filepath='stockholm')
# Download by a boundary polygon in geojson
json_file = open("stockholm_boundary.geojson")
data = json.load(json_file)
boundary_polygon = shape(data["features"][0]['geometry'])
G = ox.graph_from_polygon(boundary_polygon, network_type='drive')
save_graph_shapefile_directional(G, filepath='stockholm')地图匹配
关于FMM的使用及参数说明,帮助文档有详细的说明,这里对一些重点问题进行说明。
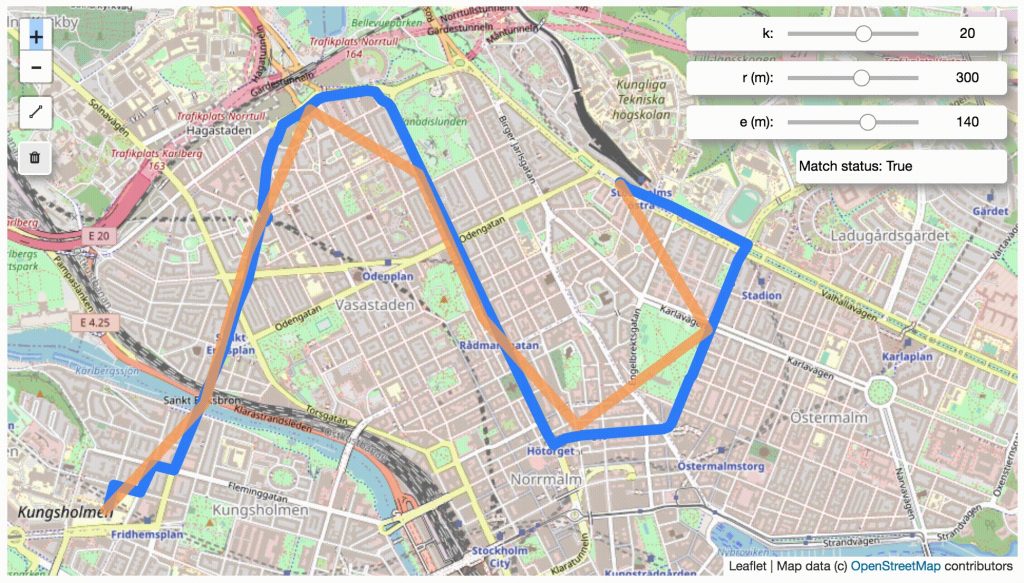
1、关于算法的选择
FMM实际包含两种算法:fmm 和 stmatch 。从算法效果来看,fmm匹配的更好,但需要消耗大量的内存和硬盘空间,fmm 需要先运行 ubodt_gen 命令以生成邻接矩阵文件,随着路网规模的增大,这个文件的大小会指数级增加,可以达到几百G甚至更高,且后续的地图匹配过程需要把这个文件读入内存,这种配置的硬件是很难达到的。因此,小规模路网匹配用fmm ,大规模路网匹配只能使用stmatch 实现。或许通过数据分拆的方式,可以解决fmm 计算资源消耗大的问题,未做进一步尝试,欢迎大家在评论区留言探讨。
2、输入说明
输入的GPS数据文件一般为csv文件,其中至少包含四个字段:经度、纬度、id和时间戳,id指的是一段gps轨迹标识符,可以理解为路径id。fmm可以直接对gps轨迹点集进行地图匹配,也可以通过gps2traj转为轨迹再进行匹配,但最终输出的结果是线性轨迹格式。在使用gps2traj进行点线转换时,应特别注意字段名前后是否有空格,这里容易出错。此外,数据准备过程中,有时会需要用到分隔符转换,可参考以下代码实现。
# 将csv分隔符从逗号转为分号
def convert_csv(input_file, output_file):
with open(input_file, 'r') as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
rows = list(csv_reader)
with open(output_file, 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file, delimiter=';')
csv_writer.writerows(rows)3、配置文件说明
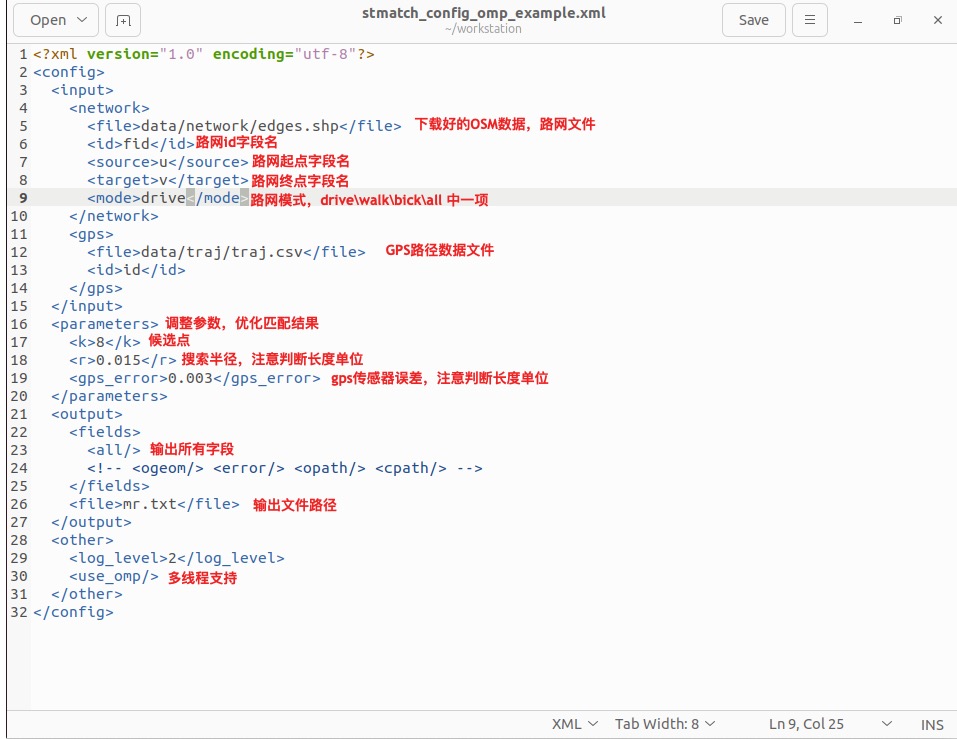
fmm 提供了多种命令运行方式,如果在本地运行,推荐使用XML配置文件的方式,方便查找错误和调参。fmm 与 stmatch 配置大致相似,可以参考以下说明进行配置。配置保存后,运行 stmatch stmatch_config_omp_example.xml 命令等待结束,即可获取匹配结果。
原创文章,作者:7right-admin,如若转载,请注明出处。